Technical Diagramming
Security Monitoring & Incident Response Architectures


Get your team started in minutes
Sign up with your work email for seamless collaboration.
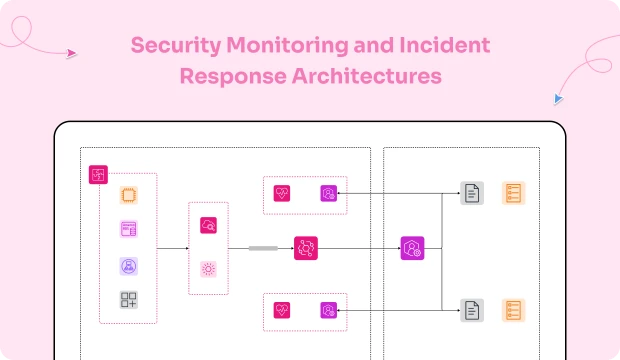
A security monitoring & incident response architecture is the blueprint that connects telemetry, analytics, and orchestrated actions into one repeatable system. It defines how you collect signals, detect adversary behavior, triage efficiently, and contain threats with confidence. Rather than ad-hoc alerts, you get engineered detections, measurable playbooks, and a feedback loop that keeps improving. The output isn’t just alerts—it’s reliable outcomes: shorter dwell time, smaller blast radius, and cleaner audit evidence.
Visualize data sources, pipelines, and actions with the Security Monitoring Architecture Template in the Security Architecture Diagram Tool. Interlink with Zero Trust Architecture, IAM Architecture, and Network Security Architecture for end-to-end coverage.

Hybrid work, SaaS adoption, and cloud-native releases have multiplied signals and attack paths. Identity abuse, supply chain issues, and API misuse slip past legacy perimeters. A modern monitoring & IR architecture normalizes telemetry, scores risk with context, and executes automated containment where it counts. You move from noisy alert queues to engineered detections backed by playbooks and service ownership. The result: faster detection, consistent response, and audit-ready evidence tied to clear business outcomes.
Effective programs are built on three principles. First, collect comprehensive telemetry with rich context so every signal is attributable to a user, device, workload, and segment. Second, prioritize detection and triage with quality rules and threat-informed analytics that reduce noise and highlight impact. Third, automate response and recovery where safe, then measure outcomes to refine controls. Together, these principles convert monitoring from reactive alerts into a disciplined, data-driven incident response capability.
Great detections start with great data. Stream endpoint, identity, network, cloud control-plane, and application logs into a normalized lake. Enrich every event with user, device posture, resource labels, and segment tags so investigations are fast and precise. Capture high-value artifacts—auth results, token lifetimes, API schemas, data classifications—because context turns “interesting” into “actionable.” With consistent schemas and retention policies, you can pivot quickly, correlate signals, and reconstruct timelines with confidence.
Detection engineering beats alert sprawl. Frame hypotheses using threat models and ATT&CK techniques, then write rules with clear severity and response guidance. Suppress duplicates, de-duplicate alerts, and group related events into cases. Triage flows should answer: what changed, who’s impacted, how confident are we? By combining ML anomaly scores with deterministic rules and human hunting, you keep noise low and attention high—so analysts focus on incidents that actually matter.
Speed is a control. Use SOAR to codify safe, reversible actions: expire tokens, quarantine hosts, rotate keys, or force re-authentication. Gate automation with confidence thresholds, approvals, or time-of-day policies. Every playbook logs evidence and notifies owners, turning “we think” into “we did.” Pair runbooks with immutable rollbacks and DR patterns so recovery is practiced, not improvised. Over time, more incidents move from manual firefighting to measured, automated containment.
This numbered map shows where signals originate, how they’re processed, and where decisions trigger action. It mirrors the Security Monitoring Architecture Template and aligns with IAM, Zero Trust, and Network Security so identity, network, and app context enrich detections consistently across environments.
Playbooks translate policy into action. Start with common, high-impact scenarios and make them safe, fast, and measurable. Each playbook should include triggers, evidence to gather, approval gates, reversible steps, and owner notifications. Below are baseline playbooks you can implement and iterate, then publish as reusable standards across teams.
Ship improvements as thin, vertical slices: one signal, one detection, one playbook, one metric. Prove value in weeks, not quarters. Then scale your pattern across domains. Use this sequence to build momentum without boiling the ocean.
Most setbacks come from great tools glued together with weak processes—or perfect processes fed by unreliable data. Use the list below as a quarterly hygiene check. Each pitfall pairs a symptom with a corrective action you can execute quickly.
Track indicators that reflect outcomes, not tool activity. Measure speed, coverage, accuracy, and automation. Publish trends monthly and tie them to shipped detections and playbooks so leadership sees progress linked to work.
A strong security monitoring & incident response architecture turns signals into decisions and decisions into action. Instrument widely, enrich with context, and engineer detections that matter. Automate safe containment, practice recovery, and measure outcomes so maturity stays visible. Build your living diagram with the Security Monitoring Architecture Template in the Security Architecture Diagram template, and interlink with Zero Trust, IAM, and Network Security for complete coverage.
1. Do I need both SIEM and SOAR?
2. How do I decide what to automate?
3. What data sources are most critical?
4. How do I avoid alert fatigue?
5. How should I test my IR plan?
Start using Cloudairy to design diagrams, documents, and workflows instantly. Harness AI to brainstorm, plan, and build—all in one platform.
Table of Contents

Introduction
 Manage all your work in one placeCollaborate with your teamUse Cloudairy for FREE—forever
Manage all your work in one placeCollaborate with your teamUse Cloudairy for FREE—forever.webp)
.webp)
.webp)


